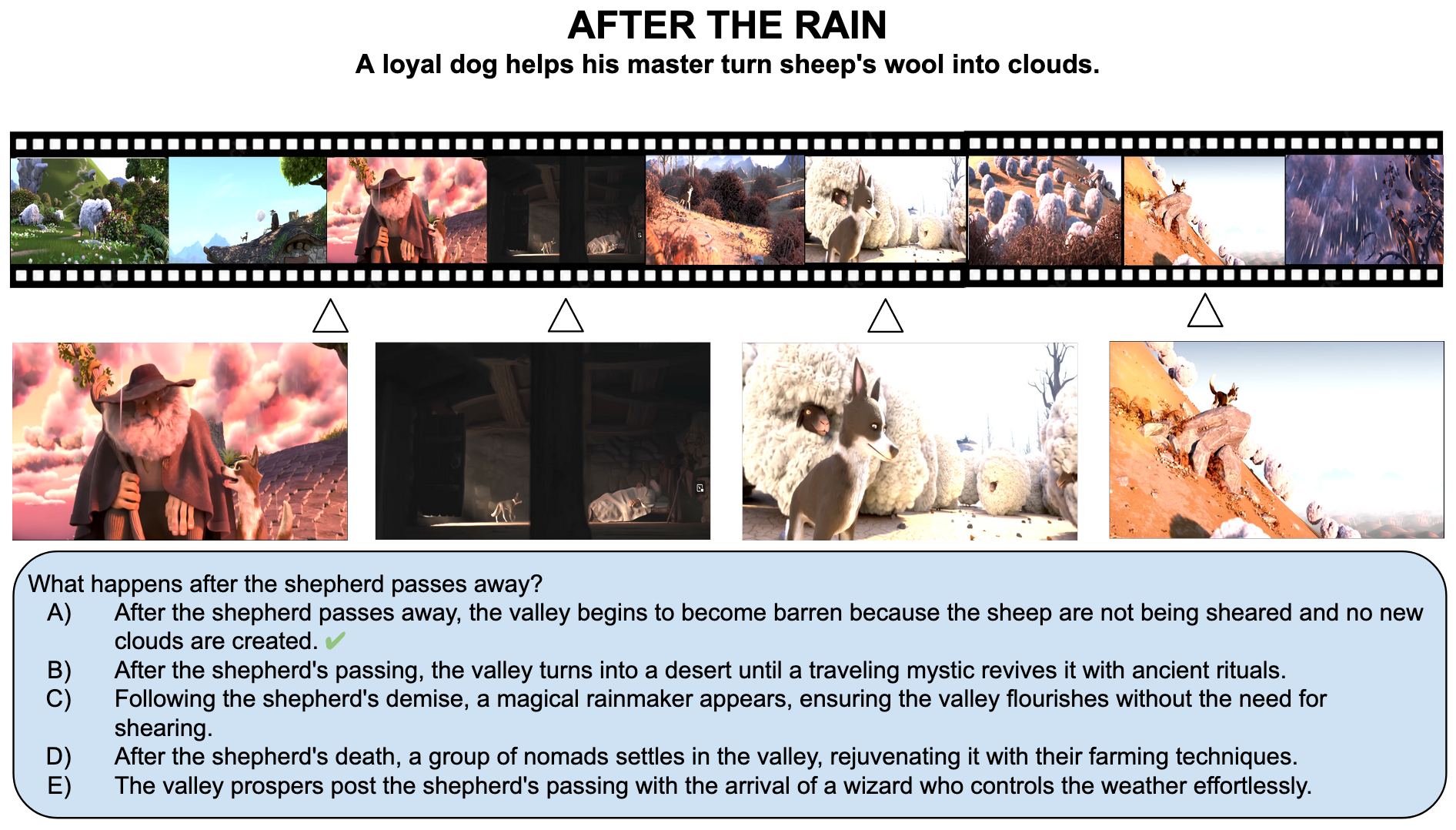
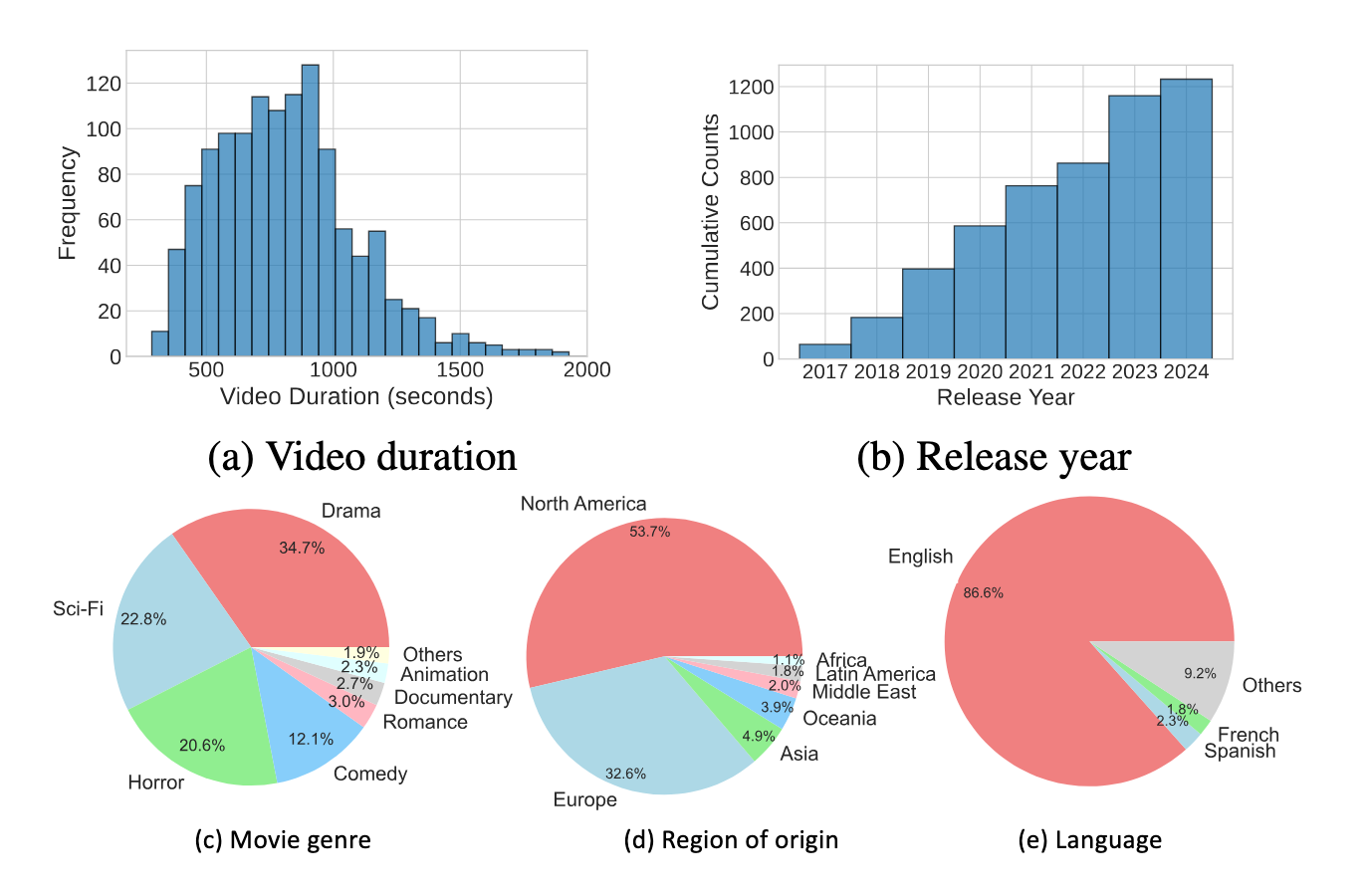
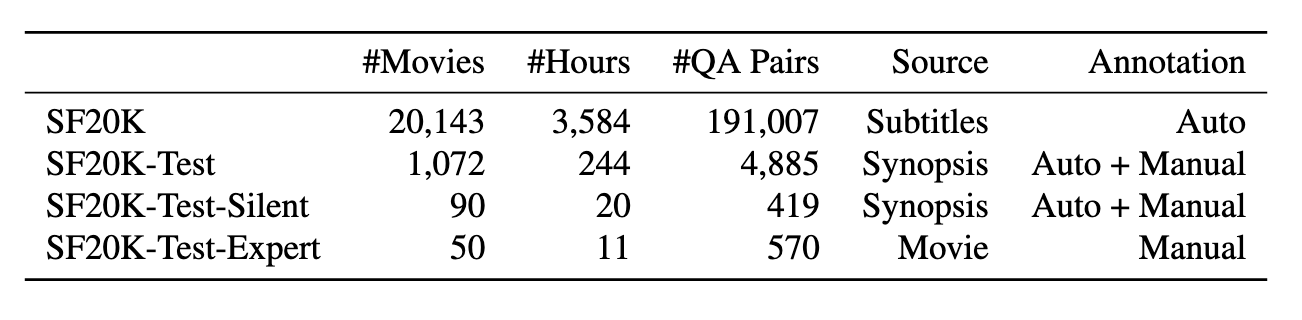
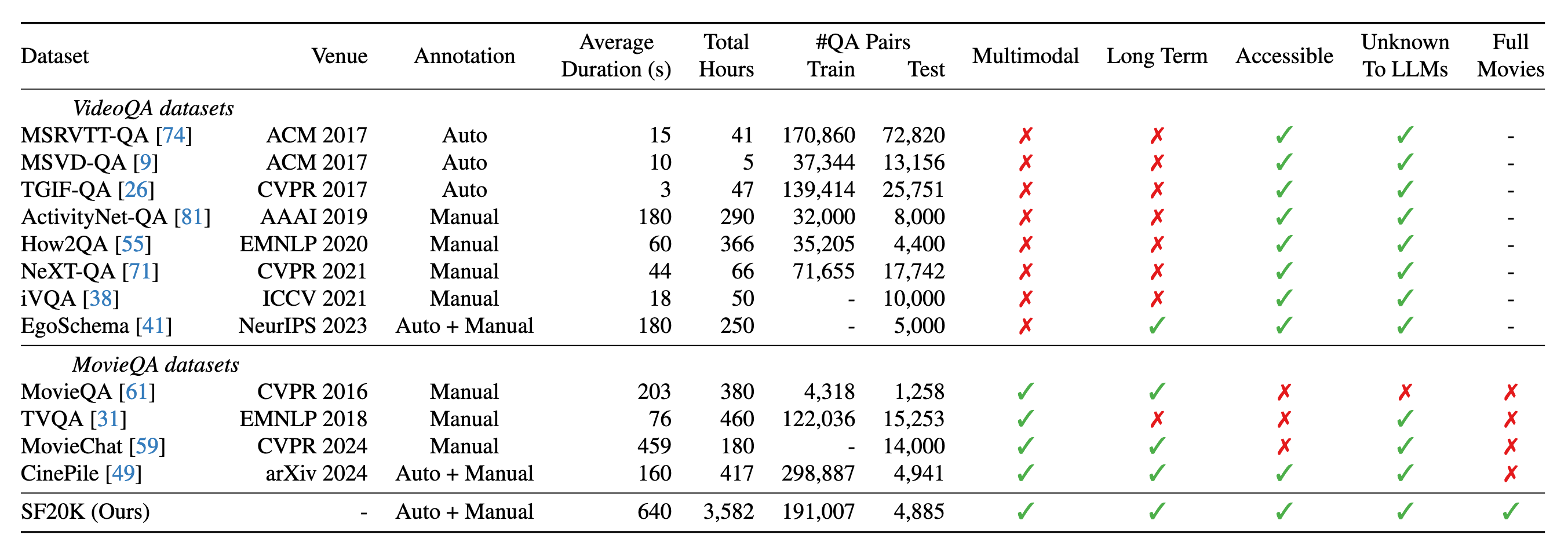
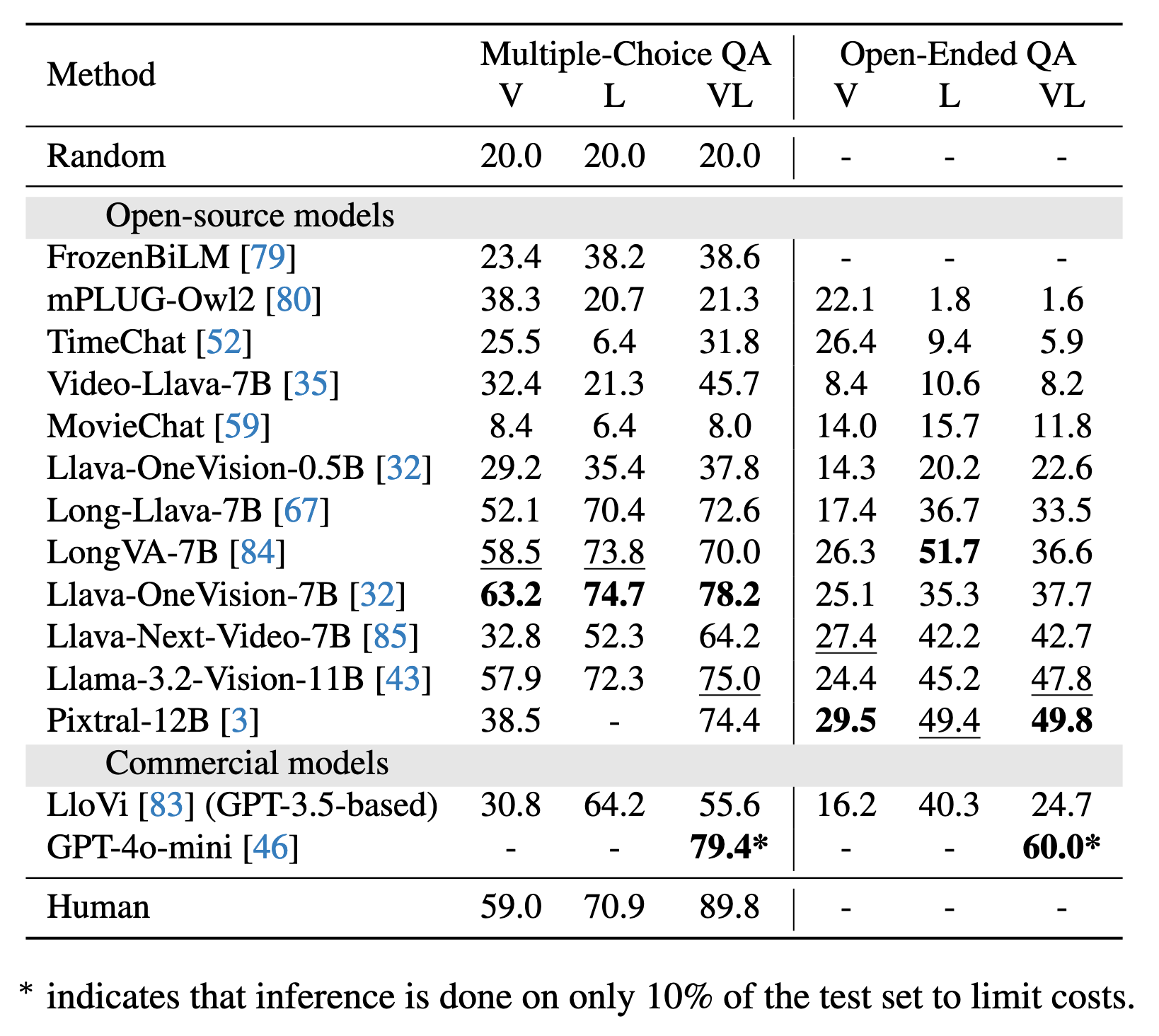
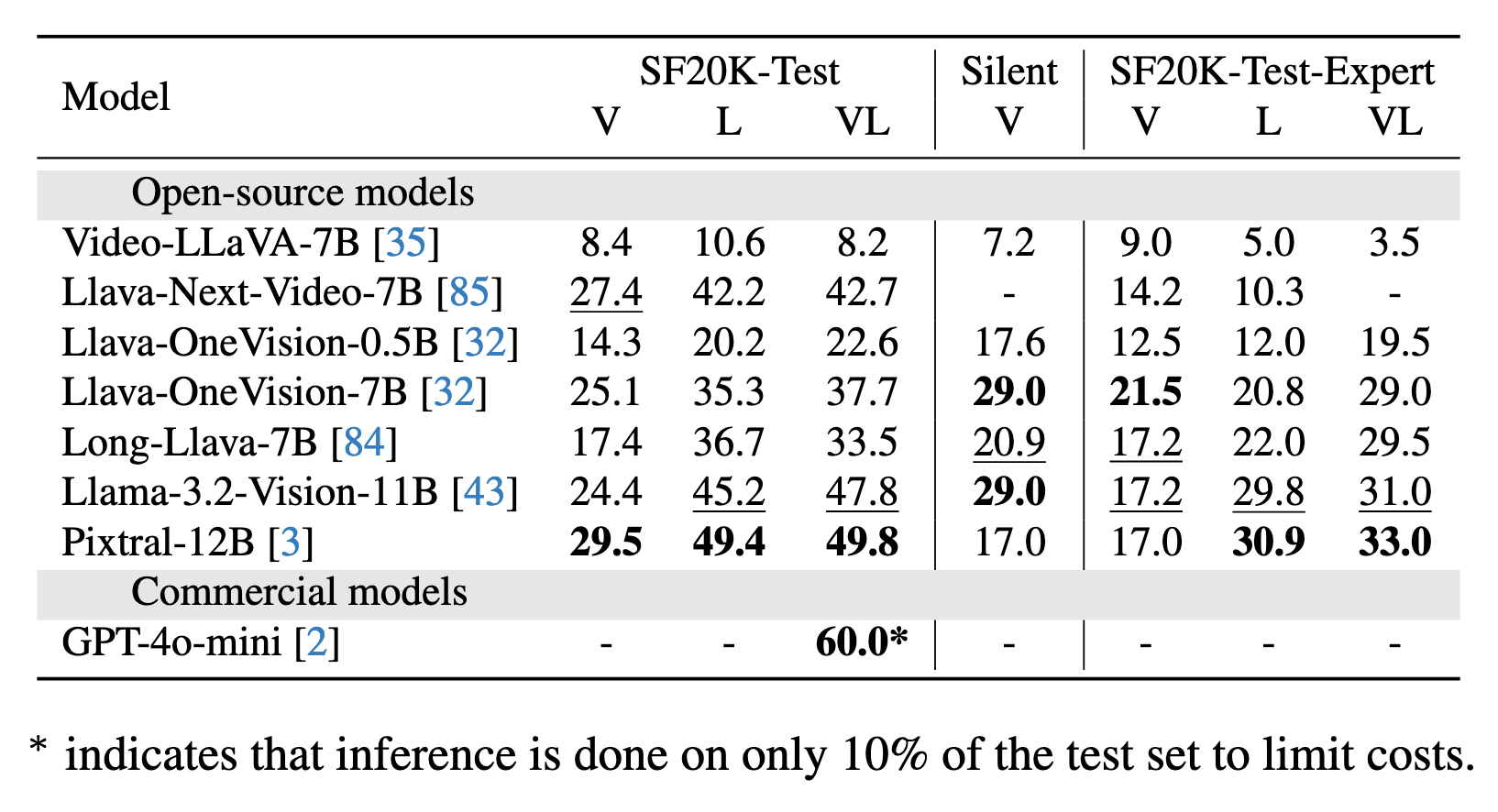
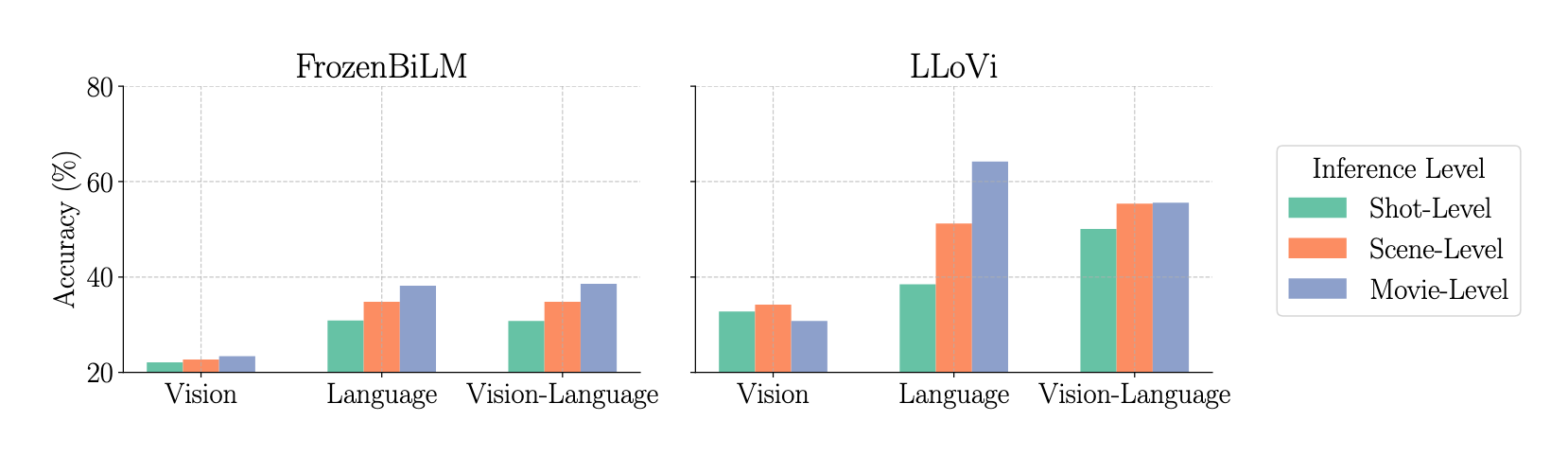
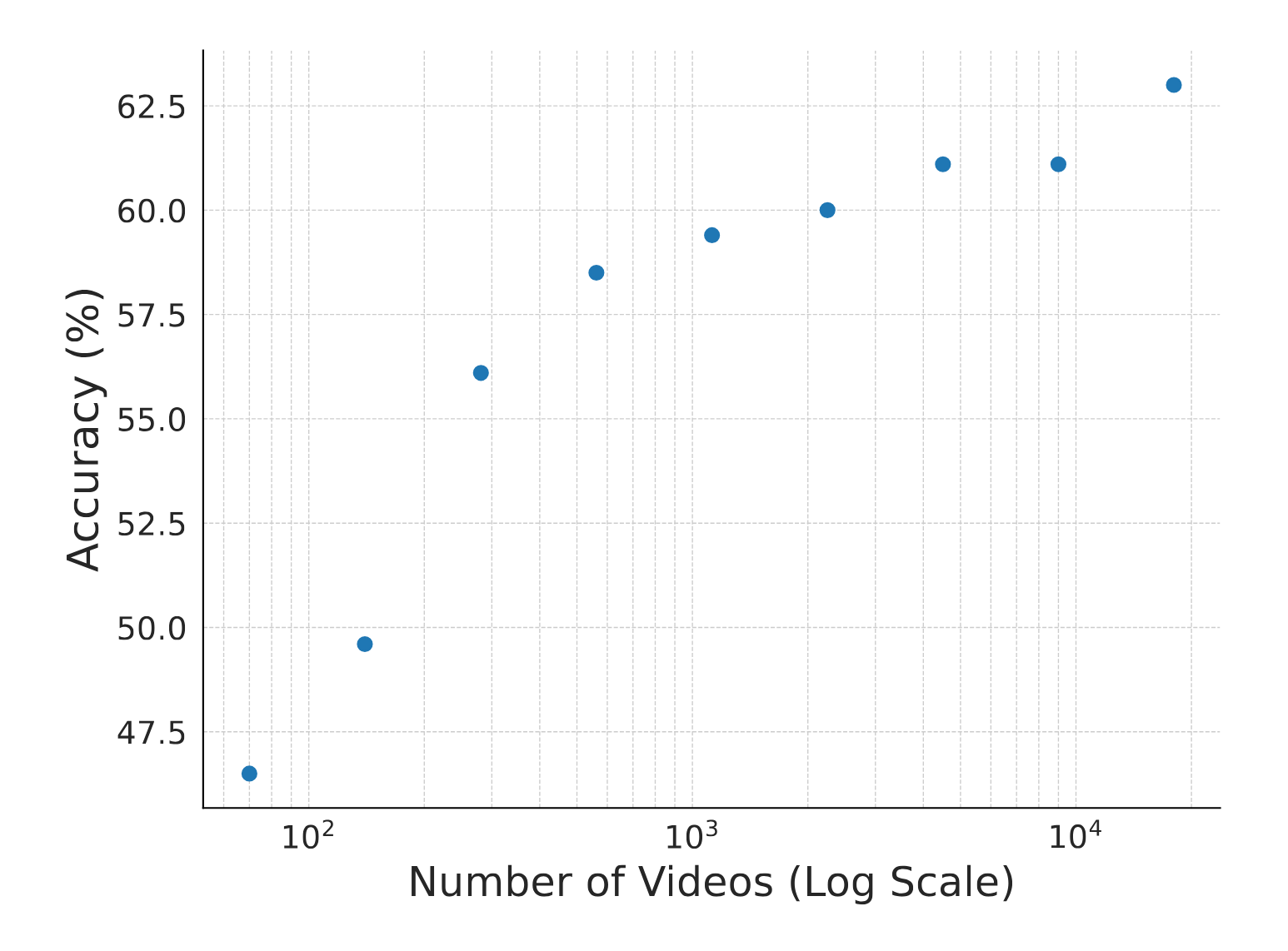
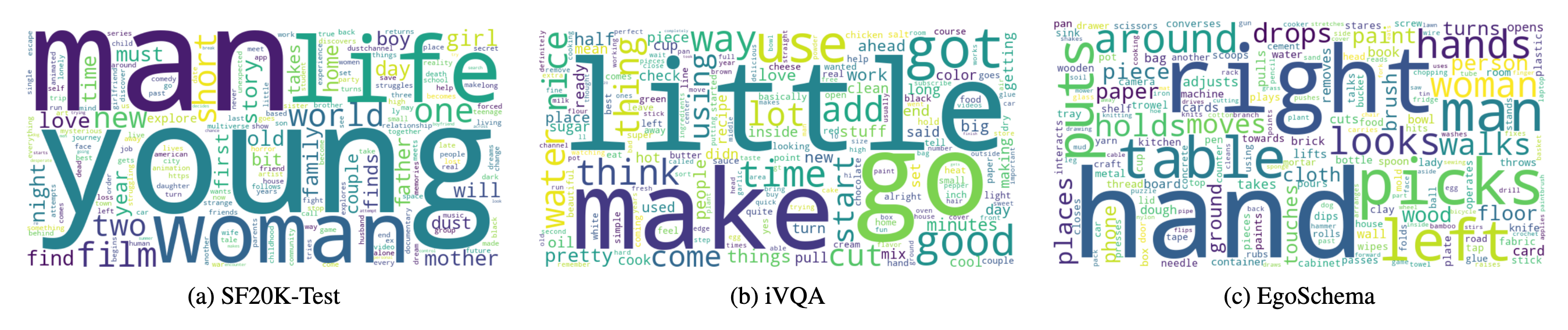MCQA: Multiple-choice question answering OEQA: Open-ended question answering
V: Vision-only (video frames) L: Language-only (subtitles) VL: Vision-language (video frames + subtitles)
| # | Model | #Params | MCQA | OEQA | ||||
|---|---|---|---|---|---|---|---|---|
| V | L | VL | V | L | VL | |||
| GPT-4o-mini | - | - | - | 79.4 | - | - | 60.0 | |
| Pixtral | 12B | 38.5 | - | 74.4 | 29.5 | 49.4 | 49.8 | |
| Llama-3.2-Vision | 11B | 57.9 | 72.3 | 75.0 | 24.4 | 45.2 | 47.8 | |
| Llava-Next-Video | 7B | 32.8 | 52.3 | 64.2 | 27.4 | 42.2 | 42.7 | |
| Llava-OneVision | 7B | 63.2 | 74.7 | 78.2 | 25.1 | 35.3 | 37.7 | |
| LongVA | 7B | 58.5 | 73.8 | 70.0 | 26.3 | 51.7 | 36.8 | |
| Long-LLaVA | 7B | 52.1 | 70.4 | 72.6 | 17.4 | 36.7 | 33.5 | |
| Llava-OneVision | 0.5B | 29.2 | 35.4 | 37.8 | 14.3 | 20.2 | 22.6 | |
| MovieChat | 7B | 8.4 | 6.4 | 8.0 | 14.0 | 15.7 | 11.8 | |
| Video-LLaVA | 7B | 32.4 | 21.3 | 45.7 | 8.4 | 10.6 | 8.2 | |
| TimeChat | 7B | 25.5 | 6.4 | 31.8 | 26.4 | 9.4 | 5.9 | |
| mPLUG-Owl2 | 7B | 38.3 | 20.7 | 21.3 | 22.1 | 1.8 | 1.6 | |
| FrozenBiLM | 0.5B | 23.4 | 38.2 | 38.6 | - | - | - | |